Pinecone x Hashnode: add semantic search to your Hashnode blog posts
Use Pinecone, OpenAI and AWS to make your blog content searchable via natural language queries

Team members
Andrea Amorosi (Hashnode | Twitter | GitHub)
Overview
Made popular together with large language models (LLMs), semantic search has proven to be a powerful new approach for providing relevant search results based on natural language queries.
Semantic search takes into account the meaning and intention behind search queries and does not rely on exact or near-exact matching of search terms to keywords.
For example, if I search for "warm-weather hat" on amazon.com, I get a lot of results for winter gear although what I'm actually looking for are hats to wear in the summer. In this case, a semantic search would be more successful in understanding my intention and can offer more relevant results.
With this Pinecone x Hashnode integration, a submission to the Hashnode APIs Hackathon in Category #1, you can easily set up semantic search for your Hashnode blog posts and query them using a serverless REST API endpoint.
To implement this, we rely on Pinecone, a managed vector database, the OpenAI API for embedding models, and AWS serverless services to host the solution in your own AWS account.
This project builds on HashBridge (GitHub) which makes it easy to set up integrations between Hashnode and AWS serverless functions with AWS Lambda.
In the rest of this blog post, we go into more detail on how you can set up and use the Pinecone x Hashnode integration, how it works, and the implementation decisions we made.
How to use Pinecone x Hashnode
If you want to get started quickly, watch this 8 minute demo to learn how to set up and use HashBridge with your Hashnode blog:
We provide detailed deployment instructions and the full source code in our GitHub repository. Your issues and contributions are very welcome!
How Pinecone x Hashnode works
The architecture of this Pinecone x Hashnode integration can roughly be split in two parts that work independently:
Content ingestion: whenever a blog post is published, updated, or deleted on our Hashnode blog, we need to update our vector database to reflect this change. In addition, we need to be able to do an initial ingestion of existing blog posts into the vector database.
Search: when a user submits a search query to our search API, we need to run a search in our vector database and return the most relevant results.
Sounds easy enough! In the following sections, we explain the architecture and underlying technical concepts of these two elements in detail. But first, let's do a quick primer on semantic search and vector embeddings.
Primer: semantic search and vector embeddings
Vector embeddings are the basis for semantic search. A vector embedding is a series of numbers (a vector) in a vector space that represents an object such as a word, sentence, or entire document. Each object is a point with a certain position in the vector space. By measuring the distance between points, we can assess and compare their similarity.
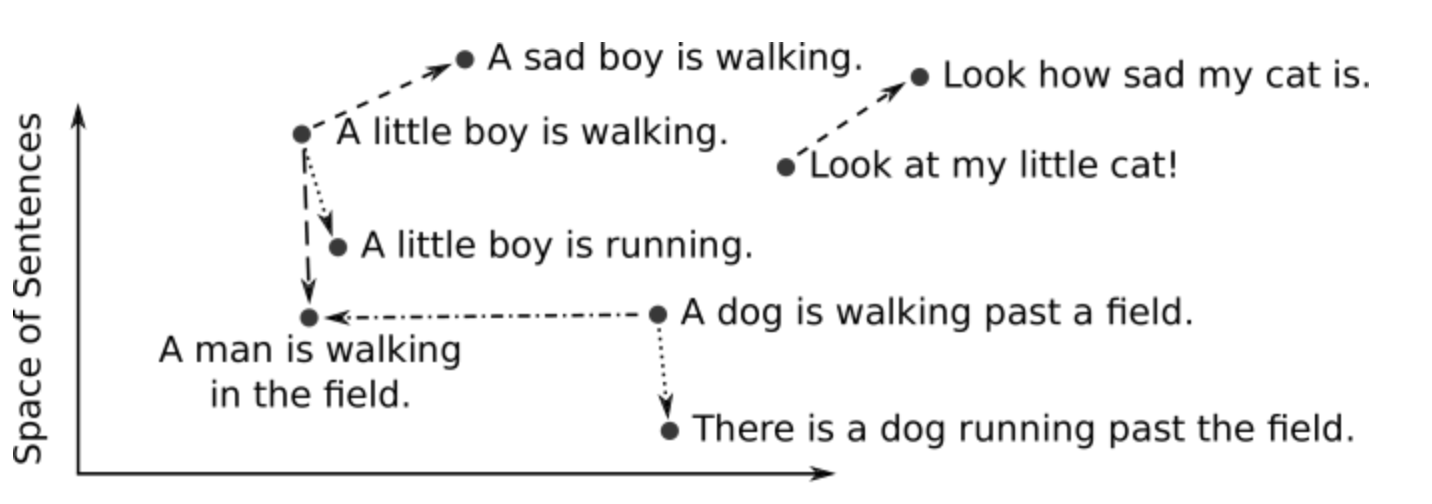
Similar sentences are positioned close-by in the vector space (Source:DeepAI).
In case of semantic search, we can use this to our advantage. We generate vector embeddings for our Hashnode blog posts which positions them in the vector space. When a user inputs a search query, we also generate a vector embedding that represents the query. Finally, we can compare the position of the search query with the positions of our blog content and find the content that is closest and therefore most similar to the query.
To generate vector embeddings, we can use an embedding model. This type of LLM takes a text input and returns a vector with a certain number of dimensions. Besides countless open-source models that you can host yourself, there are also managed models available from OpenAI or via Amazon Bedrock.
Ingesting Hashnode events and storing vector embeddings in Pinecone
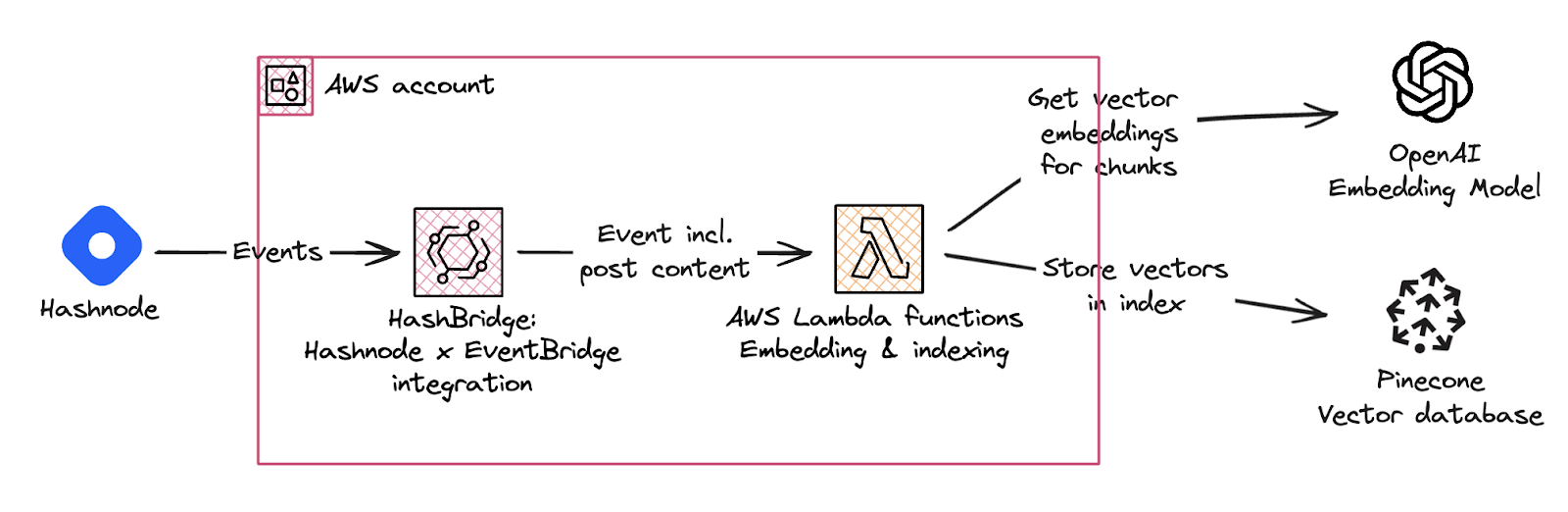
Because this integration builds on HashBridge (GitHub), we already have a way to receive webhook events from Hashnode on an EventBridge event bus in our AWS account which triggers a serverless AWS Lambda function. HashBridge uses the Hashnode GraphQL API to enrich webhook events with additional data and metadata such as blog post content in markdown, author, URL, and more.
A Lambda function, written in TypeScript, contains our logic for generating embeddings and communicating with the Pinecone vector database.
Pinecone is a fully-managed vector database that enables AI use cases like semantic search, retrieval-augmented generation (RAG), and more. The database is integrated with popular frameworks like LangChain and LlamaIndex and offers clients for Python, Node.js, and Java as well as a REST API.
Pinecone offers both pod-based and serverless pricing options, the latter in preview. We tested this integration with the pod-based free tier but it should work similar in case of the serverless option.
One challenge when generating vector embeddings is the context size supported by embedding models. OpenAI’s ext-embedding-3-small embedding model, which we are using here, supports up to 8191 input tokens, which translates to roughly 32,000 characters in case of English-language text.
This means that for blog posts with more than 32,000 characters, we need to split the content into multiple chunks. We also need to consider that we are embedding the markdown content instead of text content to not lose URLs or code formatting metadata. Depending on the use case, different chunking strategies can be applied to improve retrieval accuracy. This Pinecone blog post goes into more detail.
In our case, we decide to break the markdown blog content into chunks of 500 characters with an overlap of 50 characters before generating vector embeddings for each chunk. LangChain’s Markdown splitter helps with keeping text with common context together during chunking based on the Markdown document structure.
To store these chunks which all make up one blog post, we follow Pinecone’s recommendation of upserting each chunk separately as a distinct record. We use ID prefixes to connect each chunk to its parent document. The resulting structure looks something like this:
{"id": "blogid1#chunk1", "values": [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, ...]},
{"id": "blogid1#chunk2", "values": [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, ...]},
{"id": "blogid1#chunk3", "values": [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, ...]},
{"id": "blogid1#chunk4", "values": [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, ...]}
In addition to embedding new posts, you might already have a whole bunch of posts in your Hashnode blog that you want to make searchable. In this case, you can use our initial embedding script which will perform the query, chunk, embed, and store steps necessary to get all of your blog posts into Pinecone.
To update or delete a blog post from Pinecone based on a Hashnode event, we need to be a bit more careful.
Using the search API
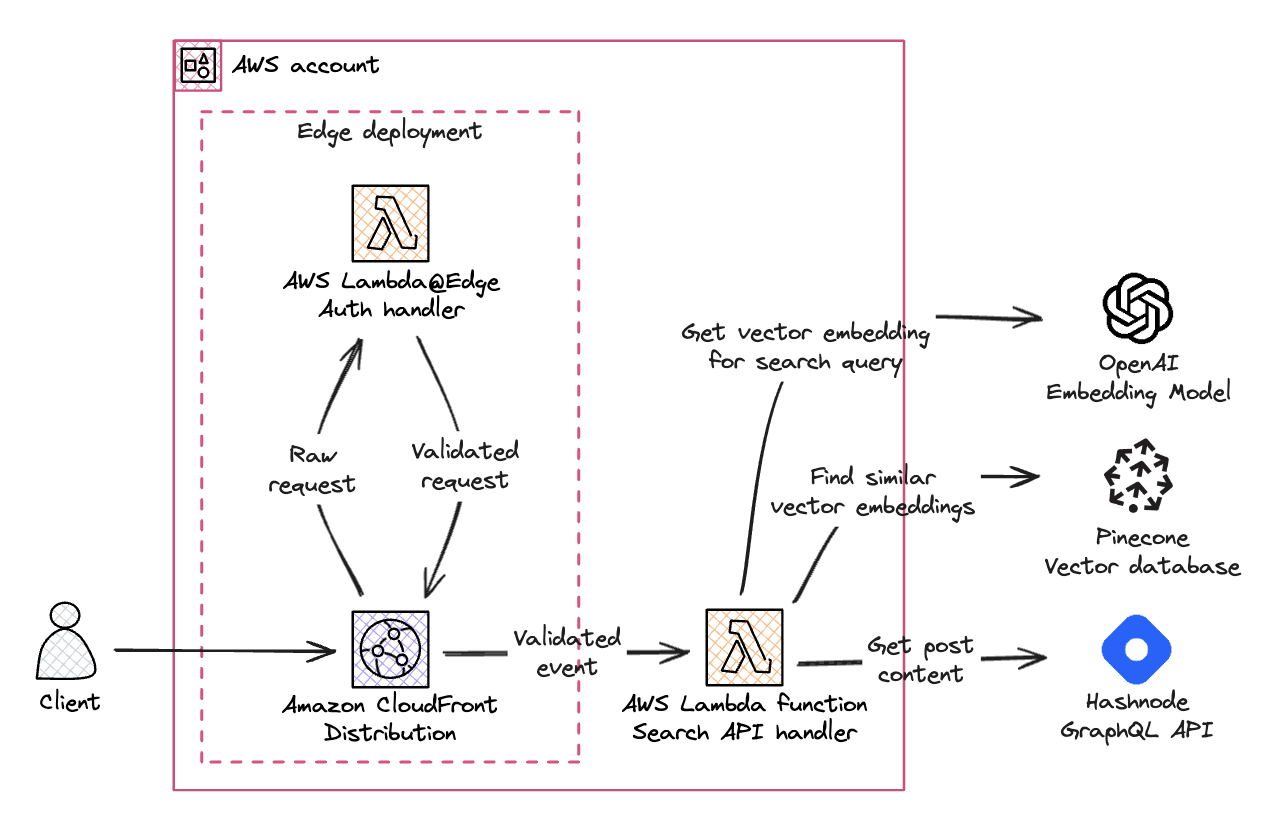
Our search API consists of a Lambda function with its function URL and IAM authentication enabled. The function URL is protected by a CloudFront distribution where a Lambda@Edge function signs each request using Sigv4. This setup is very similar to what we used to build HashBridge, so head over to the HashBridge announcement blog post and take a look at the Verifying webhook events with Lambda@Edge section for more details.
We process search queries in the Search API handler function. This function performs the following tasks:
Get vector embeddings for the search query text from OpenAI.
Run a query operation on Pinecone to identify the chunks most similar to query embeddings.
Extract the post ID from the three similar Pinecone query result chunks and use the Hashnode GraphQL API to get the post brief.
Let's look at an example where we ask a natural language question to the Hashnode Engineering Blog.
After deploying the integration, we can make a simple HTTP GET request to the search API endpoint and include our query as a URL parameter. In this case, we are using httpie to make the request from the command line for the query "peer review infra changes":
http https://dkzum3j6x4pzr.cloudfront.net/search text=="peer review infra changes"
The search API would return a response that contains the three most similar results, including their author, brief, similarity score, and more:
{
"matches": [
{
"post": {
"author": {
"name": "Shad Mirza",
"username": "iamshadmirza"
},
"brief": "Hey, everyone! If you've been using AWS, chances are you've come across CDK and building cloud apps with it. As seamless as it is to deploy apps using CDK, it is equally important to monitor changes in infrastructure code and prevent issues.\nThis gui...",
"id": "647ed1c80fce655a6be9ac07",
"title": "Simple Steps to Include CDK Diffs in GitHub PRs"
},
"similarity_score": 0.4194794
},
// 2 more matches
]
}
And, sure enough, when we check the result with the highest score, we find a relevant discussion covering the topic addressed in our query in the post content despite the exact terms not being present in the title or brief of the post (Simple Steps to Include CDK Diffs in GitHub PRs).
Conclusion
Our Pinecone x Hashnode integration makes it easy to add semantic search to your Hashnode blog. In particular if you are using Hashnode's headless mode, you may want to offer a unified semantic search experience across your existing website content and your Hashnode blog content. You can ingest all of these content types into Pinecone and our solution provides a simple but accurate search enpoint.
Let us know what you think in the comments or open a GitHub issue with any questions and feedback.
