HashBridge: extend your Hashnode blog with event-driven serverless functions
Connect your Hashnode blog to serverless AWS Lambda functions and Amazon EventBridge based on events in your Hashnode blog.

Team members
Andrea Amorosi (Hashnode | Twitter | GitHub)
Overview
When we saw the Hashnode APIs Hackathon announcement, we thought long and hard about what integration could make an impactful addition to the Hashnode ecosystem for the hackathon Category #1. With this submission, we decided to build a re-usable integration that anyone can use to extend their Hashnode blog with Amazon Web Services (AWS).
HashBridge is an integration that allows you to connect your Hashnode blog to serverless AWS Lambda functions and other resources based on events in your Hashnode blog.
Each time you publish, update or delete a blog post, you trigger a serverless function that receives blog content and metadata such as URL, author, and more as an input. Inside your function, you can then write code in the programming language of your choice that communicates with AWS services or any external API.
For example, you could use a text-to-speech service to generate an audio version of your blog post, use AI to generate a cover image, or cross-post to social media. All of this without setting up and managing your own infrastructure and at close to zero cost for running HashBridge in your own AWS account.
In the rest of this blog post, we go into more detail on how you can set up and use HashBridge, how we built it, and the implementation decisions we made.
How to use HashBridge
Use the following quick instructions to deploy HashBridge to your AWS account. For more detailed deployment instructions and the full source code, head over to the GitHub repository. Your issues and contributions are very welcome.
As a prerequisite, you need an AWS account and Node.js installed. Next, follow these four steps to set up HashBridge:
Go to your Hashnode blog dashboard, choose Webhooks and then Add New Webhook. Do not input an URL just yet but select all of the
post_*events and copy the secret value. Keep this window open and we'll come back later with the URL.Create a new secret in AWS Secrets Manager in the
us-east-1region. Choose Other type of secret and input the Hashnode webhook secret value as Plaintext and save it. Call your secrethashnode/webhook-secret. Note that while this secret needs to be inus-east-1, you can deploy the CDK stack in the next step to any AWS region.Clone the HashBridge GitHub repository, run
npm ciand deploy withnpm run cdk deploy -- --all.Copy the CloudFront URL from the CDK outputs and paste it into the URL field from step 1. Choose Create and you’re done!
That's it, you will now receive events from your Hashnode blog in your AWS account. Edit the sample consumer Lambda function to react to these events.
How HashBridge works
HashBridge uses AWS serverless services to set up a lightweight and easy-to-use integration between Hashnode, Amazon EventBridge and AWS Lambda:
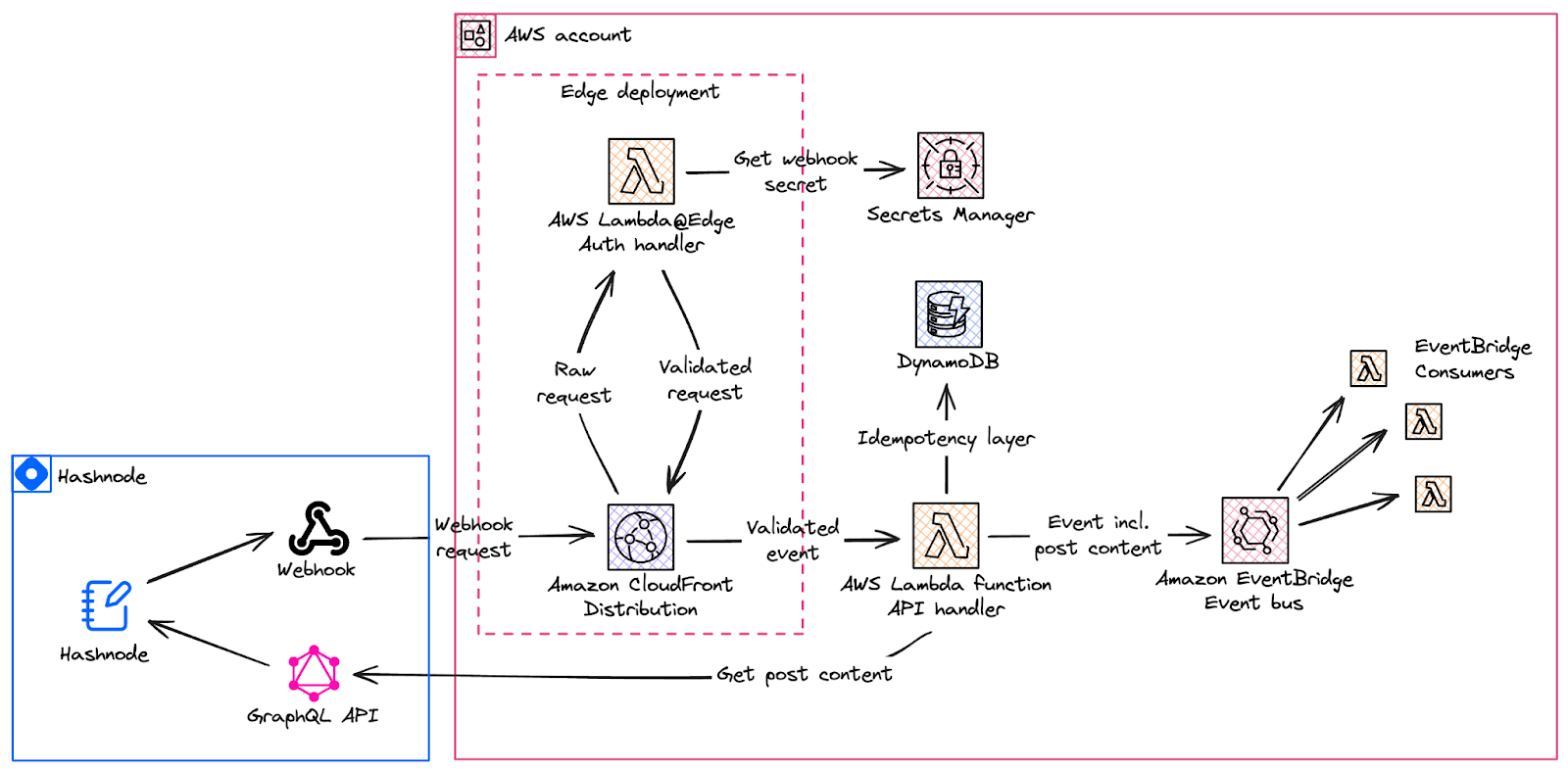
In the following sections, we explain each element of this architecture in more detail.
Hashnode webhooks and GraphQL API
On the Hashnode side, two features make HashBridge possible: webhooks and the GraphQL API.
Hashnode webhooks send an HTTP request to an API endpoint of your choice whenever you publish, update or delete a blog post or static page on your Hashnode blog. They are a great way to build event-driven integrations between your blog and third-party tools. You can then use these events to trigger static site rebuilds, post to social media, or anything else you can think of.
Hashnode’s GraphQL API lets you CRUD all aspects of your Hashnode blog, such as posts and their metadata, comments, or static pages. With this API, you can use Hashnode as a headless CMS to build your own blog frontend (e.g. using the starter kit), publish a monthly newsletter, and more.
HashBridge makes use of webhooks to receive events from Hashnode and then the GraphQL API to enrich these events with data and metadata such as a blog post’s content in markdown. You can customize the query and enrich the event to suit your needs.
Receiving webhook events with Lambda function URLs
When you activate webhooks, Hashnode will start sending events as requests to an HTTP endpoint. As we don’t want to operate a full-blown virtual machine for this, we can use serverless functions with AWS Lambda to receive and process the webhook requests, ensuring we only pay for what we need.
The easiest way to receive requests in Lambda are Lambda function URLs. A function URL is a dedicated HTTP(S) endpoint for a Lambda function and basically turns a function into a simple API endpoint.
Hashnode webhook requests contain the post ID of the blog post related to the event but they do not contain the full blog content. For example:
{
"metadata": {
"uuid": "66c9430c-1152-4243-9fa1-17478f56f2bf"
},
"data": {
"publication": {
"id": "65a965a9f60adbf4aeebde2f"
},
"post": {
"id": "65b7f792400f6e60e52d0bf2"
},
"eventType": "post_published"
}
}
To get the blog content, our Lambda function uses the Hashnode GraphQL API to query the corresponding post by id to get its content:
query {
post(id: "65b7f792400f6e60e52d0bf2") {
content {
markdown
}
}
}
When we started to work on the hackathon, this query was not yet possible. But sure enough, Hashnode created this new endpoint within just a couple of hours after hearing our feedback. That’s the new standard for customer obsession!
Finally, we publish the webhook event enriched with the post content to an EventBridge event bus from where we can then flexibly consume events inside and outside of AWS.
This allows us to receive the event once and then use it many times in multiple places. By consuming the event from the event bus, we are also decoupling the webhook verification and enrichment logic from the consuming services.
Verifying webhook events with Lambda@Edge
Many Lambda-based webhook solutions stop at this point and just leave the Lambda function URL exposed to the internet. However, as you can see in the architecture diagram, we decided to go a step further to improve the flexibility and security of our implementation.
The main reason we consider this necessary is that Lambda function URLs have limited options when it comes to authentication and security today: they only support IAM authentication, don’t allow us to restrict request headers and HTTP methods, or to set up a WAF, caching, or DDoS protection. We also can’t set up a custom domain, so if we want to replace the function later we have to update the Hashnode webhook URL as well.
To improve on these points, we set up an Amazon CloudFront distribution and define the function URL as its origin. CloudFront is a CDN which means that we directly get some benefits out of the box: we make use of the AWS global network of edge locations, get DDoS protection and a stable URL endpoint (and could even set up a custom domain).
Even better, we can now use Lambda@Edge, a serverless edge computing service, to inspect and manipulate each request that arrives at our distribution before it reaches our Lambda function URL. This way, we can verify webhook requests from Hashnode close to where they originate and before they reach our Lambda function URL.
Verifying webhook requests with Lambda@Edge
In the Lambda@Edge function, called Auth handler in our case, we want to verify that the incoming events are actually coming from Hashnode. To make this possible, we can use the x-hashnode-signature header which Hashnode sends with each webhook request. It consists of a timestamp and the actual signature:
{
"user-agent": "HashnodeWebhooks/1.0 (https://hashnode.com/)",
"content-type": "application/json",
"content-length": "187",
"accept-encoding": "gzip, deflate, br",
"x-hashnode-signature": "t=1706555289174,v1=e2971dae21c3bd9bb1ca16c842c84d3032cb0b8fd4e1e4d6dda7ff959e1243e8"
}
If we are in possession of the webhook secret, which is displayed in the Hashnode dashboard when creating the webhook, we can cryptographically verify the validity of an event’s signature and ensure it’s coming from Hashnode. Thanks to the timestamp, we are also protected from replay attacks where an attacker reuses a signature. Take a look at Hashnode’s webhook documentation to see details of how this works.
We securely store the Hashnode webhook secret in AWS Secrets Manager and access it in our Lambda@Edge function.
Besides validating that requests are actually coming from Hashnode, the Lambda@Edge function also enables us to turn on IAM authentication on the Lambda function URL so that it only accepts requests from callers with appropriate IAM permissions.
We achieve this by configuring our Lambda@Edge with the appropriate permissions and then having it sign the verified requests that we want to forward to the function URL with SigV4.
Ensuring idempotency
To make the integration more resilient against data inconsistencies, we also set up idempotency controls. Let’s imagine that you receive two identical events for the same blog post being published from the Hashnode webhook due to an error. Depending on what you built on top of Hashnode, this could mean two emails going out to customers instead of one, or two processes being launched in downstream systems.
This is where the concept of idempotency comes into play. An operation is idempotent if it can be applied multiple times without changing the result beyond the initial execution. In our case, we want to make sure that even if the same Hashnode event arrives multiple times, for example for a new blog post being published, only one event is published on the EventBridge event bus.
As our API handler Lambda function is written in TypeScript, we can simply use the idempotency utility included in the Powertools for AWS Lambda (TypeScript) to prevent the function from executing more than once on the same event payload. We use a serverless Amazon DynamoDB table as a lightweight and performant idempotency persistence layer.
Building your first serverless function based on HashBridge
To write your first serverless function that makes use of HashBridge, you can use the example function included in the HashBridge GitHub repository.
We set up this minimal example function with the Node.js runtime and TypeScript but you can adapt the CDK template to use any other Lambda runtime as well:
import type { EventBridgeEvent } from "aws-lambda";
import { Logger } from "@aws-lambda-powertools/logger";
import type { EventType, PostEvent } from "./types.js";
const logger = new Logger({ logLevel: "DEBUG" });
export const handler = (event: EventBridgeEvent<EventType, PostEvent>) => {
const eventType = event["detail-type"];
logger.debug("Received event", { eventType, event });
};
This function is subscribed to the EventBridge event bus and is triggered each time a webhook event is received from Hashnode.
Conclusion
HashBridge makes it easy to extend your Hashnode blog with event-driven serverless functions. We had a blast building HashBridge over the last two weeks and we're excited to see what you are going to build on top of it.
Reach out in the comments or via GitHub issue with any questions and feedback.
A big thank you to the Hashnode team for this Hackathon challenge and for answering our questions throughout the process.
